AI , Clean Code , dynamics-crm , low-code , powerplatform , tips
AI-Powered Summaries for Power Platform Solution Changes with GitHub Actions

When working with Power Platform, the Dev environment often holds the latest version of what your team is building. However, tracking what actually changed between exports across components, flows, and configurations is a tedious task. The diffs are noisy, the XML is unreadable, and manual review doesn't scale. Here's how I used GitHub Actions and an LLM to automate that review and produce readable summaries automatically.
Flow Explained
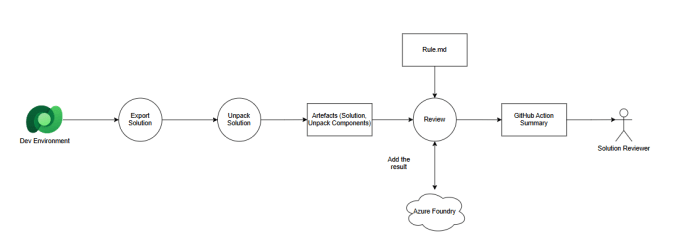 Solution flow
Solution flow
Here are the steps (important ones) of the GitHub action that we're demo-ing today:
- The trigger will be based on manual execution (workflow_dispatch) and will need one input of the solution name (solution must already exist on the targeted environment).
- It will check out the feature branch.
- Install Power Platform CLI Tools
- Export the solution using the GitHub repo secret (AZURE_OPENAI_API_KEY, PP_ENVIRONMENT_URL, PP_APP_ID, PP_CLIENT_SECRET, PP_TENANT_ID) and variables (AZURE_OPENAI_MODEL, AZURE_OPENAI_BASE_URL)
- Unpack the solution and copy the files into the specific folder
- Get the GIT changes and generate instructions based on the Rule.md file.
- Install Python
- Execute Python code to get the AI summary
- Push the changes, upload the artifacts, upload the summary, and commit
Here is the snippet of export-solution.yml:
name: Export Power Platform Solution
on:
workflow_dispatch:
inputs:
solution_name:
description: "Blog CI solution is used for demonstration purposes in the Power Platform DevOps blog series. Change this input to export a different solution. The solution must already exist in the target environment."
required: true
type: string
default: "Blog_CI"
permissions:
contents: write
jobs:
export:
name: Export ${{ inputs.solution_name }}
runs-on: ubuntu-latest
outputs:
has_changes: ${{ steps.detect_changes.outputs.has_changes }}
environment:
name: dev
steps:
- name: Checkout
uses: actions/checkout@v4
with:
token: ${{ github.token }}
persist-credentials: true
- name: Install Power Platform CLI tools
uses: microsoft/powerplatform-actions/actions-install@v1
- name: WhoAmI validation
uses: microsoft/powerplatform-actions/who-am-i@v1
with:
environment-url: ${{ secrets.PP_ENVIRONMENT_URL }}
app-id: ${{ secrets.PP_APP_ID }}
client-secret: ${{ secrets.PP_CLIENT_SECRET }}
tenant-id: ${{ secrets.PP_TENANT_ID }}
- name: Export solution
uses: microsoft/powerplatform-actions/export-solution@v1
with:
environment-url: ${{ secrets.PP_ENVIRONMENT_URL }}
app-id: ${{ secrets.PP_APP_ID }}
client-secret: ${{ secrets.PP_CLIENT_SECRET }}
tenant-id: ${{ secrets.PP_TENANT_ID }}
solution-name: ${{ inputs.solution_name }}
solution-output-file: out/${{ inputs.solution_name }}_dev_${{ github.run_number }}_unmanaged.zip
managed: false
- name: Unpack solution to src/solutions
shell: bash
run: |
mkdir -p "src/solutions"
pac_cmd="pac"
if ! command -v pac >/dev/null 2>&1; then
if [ -x "${POWERPLATFORMTOOLS_PACPATH:-}" ]; then
pac_cmd="${POWERPLATFORMTOOLS_PACPATH}"
elif [ -x "${POWERPLATFORMTOOLS_PACPATH:-}/pac" ]; then
pac_cmd="${POWERPLATFORMTOOLS_PACPATH}/pac"
else
echo "PAC CLI not found. POWERPLATFORMTOOLS_PACPATH='${POWERPLATFORMTOOLS_PACPATH:-}'"
exit 1
fi
fi
"$pac_cmd" solution unpack \
--zipfile "out/${{ inputs.solution_name }}_dev_${{ github.run_number }}_unmanaged.zip" \
--folder "src/solutions" \
--packagetype Unmanaged
- name: Copy unmanaged zip into src/solutions
shell: bash
run: |
cp \
"out/${{ inputs.solution_name }}_dev_${{ github.run_number }}_unmanaged.zip" \
"src/solutions/${{ inputs.solution_name }}_unmanaged.zip"
- name: Build review input bundle
shell: bash
run: |
mkdir -p review
git diff -- "src/solutions" > review/changes.diff || true
git status --porcelain --untracked-files=all -- "src/solutions" > review/changes.status || true
cp "src/solutions/Rule.md" review/rules.md
{
echo "Review the unpacked Power Platform solution changes."
echo
echo "Target solution: ${{ inputs.solution_name }}"
echo
echo "You must read and apply the rules from rules.md."
echo "Generate the output strictly using the section structure and scope rules defined in rules.md."
echo "Start Section 0 with the compact summary table format defined in rules.md (Action | Display Name | Physical Name)."
echo "Follow the 'Workflow Prompt Directives' section in rules.md for classification boundaries, relationship reporting rules, and naming-rule output constraints."
} > review/instructions.txt
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Generate review summary
env:
AZURE_OPENAI_API_KEY: ${{ secrets.AZURE_OPENAI_API_KEY }}
AZURE_OPENAI_BASE_URL: ${{ vars.AZURE_OPENAI_BASE_URL }}
AZURE_OPENAI_MODEL: ${{ vars.AZURE_OPENAI_MODEL }}
shell: bash
run: |
python - <<'PY'
import json
import os
import re
import difflib
from pathlib import Path
from urllib import request
def write_fallback(message: str) -> None:
Path('review/summary.md').write_text(message.strip() + '\n', encoding='utf-8')
api_key = os.environ.get('AZURE_OPENAI_API_KEY', '').strip()
base_url = os.environ.get('AZURE_OPENAI_BASE_URL', '').strip()
model = os.environ.get('AZURE_OPENAI_MODEL', '').strip()
if not api_key or not base_url or not model:
write_fallback('''
LLM review was skipped because Azure Foundry settings are incomplete.
Required configuration:
- secret: AZURE_OPENAI_API_KEY
- variable: AZURE_OPENAI_BASE_URL
- variable: AZURE_OPENAI_MODEL
Review inputs were still generated:
- review/rules.md
- review/changes.diff
- review/instructions.txt
''')
raise SystemExit(0)
instructions = Path('review/instructions.txt').read_text(encoding='utf-8')
rules = Path('review/rules.md').read_text(encoding='utf-8')
diff = Path('review/changes.diff').read_text(encoding='utf-8')
status = Path('review/changes.status').read_text(encoding='utf-8') if Path('review/changes.status').exists() else ''
# Build a conservative allow-list of logical-name-like tokens seen in the diff.
# Include mixed-case tokens so invalid names (for example, tmy_Price) can still be flagged.
logical_name_pattern = re.compile(r'\b[a-zA-Z][a-zA-Z0-9]{1,15}_[a-zA-Z0-9_]{2,120}\b')
allowed_components = sorted(set(logical_name_pattern.findall(diff + '\n' + status)))
allowed_components_text = '\n'.join(f'- {name}' for name in allowed_components)
if not allowed_components_text:
allowed_components_text = '- (none detected)'
normalized_base_url = base_url.rstrip('/')
if not normalized_base_url.endswith('/openai/v1'):
write_fallback('AZURE_OPENAI_BASE_URL must end with /openai/v1 or /openai/v1/.')
raise SystemExit(0)
def call_model(system_text: str, user_text: str) -> str:
payload = {
'model': model,
'input': [
{
'role': 'system',
'content': [
{
'type': 'input_text',
'text': system_text
}
]
},
{
'role': 'user',
'content': [
{
'type': 'input_text',
'text': user_text
}
]
}
]
}
req = request.Request(
f'{normalized_base_url}/responses',
data=json.dumps(payload).encode('utf-8'),
headers={
'api-key': api_key,
'Content-Type': 'application/json'
},
method='POST'
)
with request.urlopen(req) as response:
body = json.loads(response.read().decode('utf-8'))
text_parts = []
for item in body.get('output', []):
for content in item.get('content', []):
if content.get('type') == 'output_text':
text_parts.append(content.get('text', ''))
return '\n'.join(part for part in text_parts if part).strip()
def generate_rule_review(user_text: str) -> str:
return call_model(
(
'You are reviewing unpacked Microsoft Power Platform solution changes. '
'Follow the provided rules exactly and produce a detailed, evidence-based review. '
'Never invent components. Only use component logical names that appear in the provided allow-list or are directly present in the diff. '
'Do not auto-correct or normalize logical names (including spelling). Preserve exact logical names from the evidence. '
'If no in-scope custom components exist, explicitly say so.'
),
user_text,
)
base_user_text = (
instructions
+ '\n\n--- RULES ---\n' + rules
+ '\n\n--- GIT STATUS ---\n' + (status if status.strip() else '(none)')
+ '\n\n--- ALLOWED COMPONENTS (FROM DIFF) ---\n' + allowed_components_text
+ '\n\nUse only names from ALLOWED COMPONENTS (FROM DIFF and GIT STATUS). If no allowed custom components are present, state no in-scope changes.'
+ '\n\n--- DIFF ---\n' + diff
)
try:
summary = generate_rule_review(base_user_text)
except Exception as exc:
write_fallback(f'LLM review request failed: {exc}')
raise SystemExit(0)
def get_unknown_components(text: str) -> list[str]:
found = set(logical_name_pattern.findall(text))
if not found:
return []
allowed_set = set(allowed_components)
return sorted(name for name in found if name not in allowed_set)
def replace_near_matches(text: str, unknown_names: list[str]) -> tuple[str, list[tuple[str, str]], list[str]]:
if not unknown_names or not allowed_components:
return text, [], unknown_names
replacements: list[tuple[str, str]] = []
unresolved: list[str] = []
updated = text
for unknown_name in unknown_names:
matches = difflib.get_close_matches(unknown_name, allowed_components, n=1, cutoff=0.90)
if not matches:
unresolved.append(unknown_name)
continue
target = matches[0]
# Replace whole-token occurrences only.
updated = re.sub(rf'\b{re.escape(unknown_name)}\b', target, updated)
replacements.append((unknown_name, target))
return updated, replacements, unresolved
unknown = get_unknown_components(summary)
# Auto-repair near-spelling variants (for example, oderdetail -> orderdetail) to avoid false blocks.
if unknown:
summary, auto_replacements, unresolved_after_repair = replace_near_matches(summary, unknown)
unknown = unresolved_after_repair
if auto_replacements:
summary = (
summary.rstrip()
+ '\n\nNOTE: Logical name normalization guard auto-corrected near matches to evidence-backed names: '
+ ', '.join([f'{src} -> {dst}' for src, dst in auto_replacements])
)
# Retry once with a strict correction prompt if hallucinated names are found.
if unknown:
correction_text = (
base_user_text
+ '\n\nThe previous answer was invalid because it referenced components not found in the diff: '
+ ', '.join(unknown)
+ '. Regenerate the full answer using only allowed components. Do not include any other logical names.'
)
try:
summary = generate_rule_review(correction_text)
except Exception:
pass
unknown = get_unknown_components(summary)
if unknown:
summary = (
'LLM review was blocked because the generated output referenced components not present in the diff.\n\n'
+ 'Unknown components: ' + ', '.join(unknown) + '\n\n'
+ 'Allowed components detected from diff:\n' + allowed_components_text + '\n\n'
+ 'No trusted rules summary was produced for this run. Please review the diff manually or rerun.'
)
def normalize_markdown_tables(text: str) -> str:
lines = text.splitlines()
output: list[str] = []
i = 0
def is_table_row(line: str) -> bool:
stripped = line.strip()
return stripped.startswith('|') and stripped.endswith('|') and stripped.count('|') >= 2
def parse_cells(line: str) -> list[str]:
stripped = line.strip()
return [cell.strip() for cell in stripped[1:-1].split('|')]
def is_separator_line(line: str) -> bool:
cells = parse_cells(line)
if not cells:
return False
for cell in cells:
compact = cell.replace(' ', '')
if not compact or any(ch not in '-:' for ch in compact):
return False
return True
def fmt_row(cells: list[str]) -> str:
return '| ' + ' | '.join(cell.strip() for cell in cells) + ' |'
while i < len(lines):
if not is_table_row(lines[i]):
output.append(lines[i])
i += 1
continue
start = i
while i < len(lines) and is_table_row(lines[i]):
i += 1
block = lines[start:i]
if len(block) < 2 or not is_separator_line(block[1]):
output.extend(block)
continue
header_cells = parse_cells(block[0])
if not header_cells:
output.extend(block)
continue
col_count = len(header_cells)
output.append(fmt_row(header_cells))
output.append('| ' + ' | '.join(['---'] * col_count) + ' |')
for row_line in block[2:]:
row_cells = parse_cells(row_line)
if len(row_cells) < col_count:
row_cells.extend([''] * (col_count - len(row_cells)))
elif len(row_cells) > col_count:
row_cells = row_cells[:col_count]
output.append(fmt_row(row_cells))
return '\n'.join(output)
def has_uppercase(value: str) -> bool:
return any(ch.isalpha() and ch.isupper() for ch in value)
def collect_case_violations(text: str) -> list[tuple[str, str, str, str]]:
# Returns tuples: (component, component_type, reason, suggested_fix)
violations: dict[tuple[str, str], tuple[str, str]] = {}
table_pattern = re.compile(
r'(?im)^\s*(?:Added|Updated|Modified|Deleted)\s+table\s+([A-Za-z][A-Za-z0-9]{1,15}_[A-Za-z0-9_]+)\b'
)
attr_row_pattern = re.compile(
r'(?im)^\s*\|\s*([A-Za-z][A-Za-z0-9]{1,15}_[A-Za-z0-9_]+)\s*\|'
)
for name in table_pattern.findall(text):
if has_uppercase(name):
violations[(name, 'Table')] = (
'Contains uppercase letters; physical names must be lowercase [a-z0-9_].',
name.lower(),
)
for name in attr_row_pattern.findall(text):
# Skip the Section 0 header token if it ever matches by accident.
if name.lower() in {'physicalname'}:
continue
if has_uppercase(name):
violations[(name, 'Attribute - Other')] = (
'Contains uppercase letters; physical names must be lowercase [a-z0-9_].',
name.lower(),
)
result: list[tuple[str, str, str, str]] = []
for (component, component_type), (reason, suggestion) in sorted(violations.items()):
result.append((component, component_type, reason, suggestion))
return result
def build_naming_section(violations: list[tuple[str, str, str, str]]) -> str:
if not violations:
return '## RULE EVALUATION (NAMING RULES)\nNo naming-rule violations found.'
lines = ['## RULE EVALUATION (NAMING RULES)']
for component, component_type, reason, suggestion in violations:
lines.extend([
f'COMPONENT: {component}',
f'TYPE: {component_type}',
'RULE VIOLATED: PhysicalName must be in lowercase',
'SEVERITY: ERROR',
f'REASON: {reason}',
f'SUGGESTED FIX: {suggestion}',
'',
])
return '\n'.join(lines).rstrip()
def remove_section(text: str, heading: str) -> str:
section_pattern = re.compile(
rf'(?is)(?:^|\n)\s*##?\s*{re.escape(heading)}\s*\n.*?(?=(?:\n\s*##?\s*[A-Z][^\n]*\n)|\Z)'
)
return section_pattern.sub('\n', text).strip()
def replace_or_append_section(text: str, heading: str, replacement: str) -> str:
section_pattern = re.compile(
rf'(?is)(?:^|\n)\s*##?\s*{re.escape(heading)}\s*\n.*?(?=(?:\n\s*##?\s*[A-Z][^\n]*\n)|\Z)'
)
if section_pattern.search(text):
return section_pattern.sub('\n' + replacement + '\n', text).strip()
return (text.rstrip() + '\n\n' + replacement).strip()
def normalize_line_indentation(text: str) -> str:
normalized_lines: list[str] = []
for line in text.splitlines():
stripped = line.lstrip()
if stripped.startswith('|') or stripped.startswith('##') or stripped.startswith('COMPONENT:') or stripped.startswith('TYPE:') or stripped.startswith('RULE VIOLATED:') or stripped.startswith('SEVERITY:') or stripped.startswith('REASON:') or stripped.startswith('SUGGESTED FIX:'):
normalized_lines.append(stripped)
else:
normalized_lines.append(line)
return '\n'.join(normalized_lines)
def normalize_relationship_display_names(text: str) -> str:
relationship_pattern = re.compile(
r'(?im)^\s*(?:Added|Updated|Modified|Deleted)\s+relationship\s+([A-Za-z][A-Za-z0-9]{1,15}_[A-Za-z0-9_]+)\b'
)
relationships = set(relationship_pattern.findall(text))
if not relationships:
return text
lines = text.splitlines()
normalized: list[str] = []
for line in lines:
stripped = line.strip()
if stripped.startswith('|') and stripped.endswith('|') and stripped.count('|') >= 4:
cells = [cell.strip() for cell in stripped[1:-1].split('|')]
if len(cells) == 3:
action, display_name, physical_name = cells
if physical_name in relationships and display_name == physical_name:
display_name = f'Relationship: {physical_name}'
line = f'| {action} | {display_name} | {physical_name} |'
normalized.append(line)
return '\n'.join(normalized)
def normalize_component_list_lines(text: str) -> str:
# Convert list-marked component lines to plain lines so subsequent tables render.
return re.sub(
r'(?im)^\s*-\s+((?:Added|Updated|Modified|Deleted)\s+(?:table|app module|flow/process|relationship)\b.*)$',
r'\1',
text,
)
def enforce_table_block_spacing(text: str) -> str:
lines = text.splitlines()
out: list[str] = []
def is_table_line(line: str) -> bool:
stripped = line.strip()
return stripped.startswith('|') and stripped.endswith('|') and stripped.count('|') >= 2
in_table_block = False
for line in lines:
current_is_table = is_table_line(line)
if current_is_table:
# Add one blank line before the start of a table block.
if not in_table_block and out and out[-1].strip() != '':
out.append('')
out.append(line.strip())
in_table_block = True
else:
# Add one blank line after a table block when prose follows.
if in_table_block and line.strip() != '':
out.append('')
out.append(line)
in_table_block = False
# Collapse 3+ blank lines to at most 2.
collapsed: list[str] = []
blank_run = 0
for line in out:
if line.strip() == '':
blank_run += 1
if blank_run <= 2:
collapsed.append('')
else:
blank_run = 0
collapsed.append(line)
return '\n'.join(collapsed).strip()
summary = normalize_markdown_tables(summary)
summary = normalize_component_list_lines(summary)
summary = enforce_table_block_spacing(summary)
summary = normalize_relationship_display_names(summary)
summary = normalize_line_indentation(summary)
deterministic_violations = collect_case_violations(summary)
naming_section = build_naming_section(deterministic_violations)
summary = remove_section(summary, 'RULE EVALUATION MATRIX')
summary = remove_section(summary, 'FINDINGS (NAMING RULES)')
summary = replace_or_append_section(summary, 'RULE EVALUATION (NAMING RULES)', naming_section)
if not summary:
summary = 'No LLM summary was returned.'
Path('review/summary.md').write_text(summary + '\n', encoding='utf-8')
PY
- name: Publish review summary
shell: bash
run: |
{
echo "## LLM Review Summary"
echo
cat review/summary.md
} >> "$GITHUB_STEP_SUMMARY"
- name: Detect solution changes
id: detect_changes
shell: bash
run: |
solution_path="src/solutions"
status_output="$(git status --porcelain --untracked-files=all -- "$solution_path")"
if [ -n "$status_output" ]; then
echo "has_changes=true" >> "$GITHUB_OUTPUT"
added_or_untracked="$(printf '%s\n' "$status_output" | grep -E '^A |^\?\? ' || true)"
modified="$(printf '%s\n' "$status_output" | grep -E '^ M|^M |^MM|^AM|^ T|^T ' || true)"
deleted="$(printf '%s\n' "$status_output" | grep -E '^ D|^D ' || true)"
added_count="$(printf '%s\n' "$added_or_untracked" | sed '/^$/d' | wc -l | tr -d ' ')"
modified_count="$(printf '%s\n' "$modified" | sed '/^$/d' | wc -l | tr -d ' ')"
deleted_count="$(printf '%s\n' "$deleted" | sed '/^$/d' | wc -l | tr -d ' ')"
{
echo "## Git Change Detection (Commit/Push Decision Only)"
echo
echo "This section is from git status and is not the rules-based table/attribute review summary."
echo
echo "Changes were detected under $solution_path."
echo
echo "### Change Counts"
echo
echo "- Added or untracked: $added_count"
echo "- Modified: $modified_count"
echo "- Deleted: $deleted_count"
echo
if [ -n "$added_or_untracked" ]; then
echo "### Added or Untracked Files"
echo
echo '```'
printf '%s\n' "$added_or_untracked"
echo '```'
echo
fi
if [ -n "$modified" ]; then
echo "### Modified Files"
echo
echo '```'
printf '%s\n' "$modified"
echo '```'
echo
fi
if [ -n "$deleted" ]; then
echo "### Deleted Files"
echo
echo '```'
printf '%s\n' "$deleted"
echo '```'
echo
fi
echo "### Raw Git Status"
echo
echo '```'
printf '%s\n' "$status_output"
echo '```'
} >> "$GITHUB_STEP_SUMMARY"
else
echo "has_changes=false" >> "$GITHUB_OUTPUT"
{
echo "## Git Change Detection (Commit/Push Decision Only)"
echo
echo "This section is from git status and is not the rules-based table/attribute review summary."
echo
echo "No changes were detected under $solution_path."
} >> "$GITHUB_STEP_SUMMARY"
fi
- name: Automatic push status
shell: bash
run: |
if [ "${{ steps.detect_changes.outputs.has_changes }}" = "true" ]; then
echo "Changes detected. Automatic commit/push will run in the next job." >> "$GITHUB_STEP_SUMMARY"
else
echo "No changes detected, so there is nothing to commit/push." >> "$GITHUB_STEP_SUMMARY"
fi
- name: Upload exported zip
uses: actions/upload-artifact@v4
with:
name: ${{ inputs.solution_name }}-dev
path: out/*.zip
if-no-files-found: error
- name: Upload unpacked solution folder
uses: actions/upload-artifact@v4
with:
name: ${{ inputs.solution_name }}-dev-unpacked
path: src/solutions
if-no-files-found: error
- name: Upload review bundle
uses: actions/upload-artifact@v4
with:
name: ${{ inputs.solution_name }}-dev-review
path: review/**
if-no-files-found: error
push_changes:
name: Commit and push changes
runs-on: ubuntu-latest
needs: export
if: ${{ needs.export.outputs.has_changes == 'true' }}
permissions:
contents: write
steps:
- name: Checkout
uses: actions/checkout@v4
with:
token: ${{ github.token }}
persist-credentials: true
- name: Download unpacked solution artifact
uses: actions/download-artifact@v4
with:
name: ${{ inputs.solution_name }}-dev-unpacked
path: _artifact
- name: Sync artifact content into src/solutions
shell: bash
run: |
source_dir=""
target_dir="src/solutions"
if [ -d "_artifact/src/solutions" ]; then
source_dir="_artifact/src/solutions"
elif [ -d "_artifact/Entities" ] || [ -d "_artifact/Other" ] || [ -d "_artifact/AppModules" ]; then
source_dir="_artifact"
fi
if [ -z "$source_dir" ]; then
echo "Expected artifact content not found under _artifact/src/solutions or _artifact root."
echo "Downloaded artifact layout:"
find _artifact -maxdepth 5 -type d 2>/dev/null || true
exit 1
fi
rm -rf "$target_dir"
mkdir -p "$target_dir"
cp -a "$source_dir"/. "$target_dir"/
- name: Commit and push unmanaged zip + unpacked solution changes
shell: bash
run: |
if [ "${GITHUB_REF_TYPE}" != "branch" ]; then
echo "This workflow can only push when triggered from a branch ref."
exit 1
fi
branch="${GITHUB_REF_NAME}"
if [ "$branch" = "main" ] || [ "$branch" = "master" ]; then
echo "Refusing to auto-push to '$branch'. Run this workflow from a feature branch."
exit 1
fi
git config user.name "github-actions[bot]"
git config user.email "41898282+github-actions[bot]@users.noreply.github.com"
if [ ! -d "src/solutions" ]; then
echo "Expected solution content not found under src/solutions."
echo "Downloaded artifact layout:"
find _artifact -maxdepth 5 -type d 2>/dev/null || true
exit 1
fi
git add -A "src/solutions"
if git diff --cached --quiet; then
echo "No solution changes detected to commit."
exit 0
fi
git commit -m "chore(${{ inputs.solution_name }}): export unmanaged zip and unpacked solution (run ${{ github.run_number }})"
git push origin "HEAD:${branch}"
Rule.md
You can adjust the Rule.md to whatever you want. Basically, on this sample, I want to standardize the naming convention following this logic:
- All table names and attributes (for custom) to be all in lower case (I don't like when doing code in Low Code, and the naming of the attribute to be Tmy_Price)
- Lookup attribute must end with Id (e.g tmy_contactid)
And inside this, also got various rules that the LLM needs to follow:
# Power Platform Review Rules
## Overview
This document defines the review logic for unpacked Power Platform solution changes.
- **Change summary scope:** All supported solution component types (tables, attributes, app modules, flows/processes, relationships, web resources, etc.).
- **Naming rule scope:** Custom tables and custom attributes only (publisher-prefixed components such as `tmy_`).
- **System component naming:** System tables/attributes are excluded from naming-rule violations.
---
## Scope
| Scope Area | Component Type | In Scope | Notes |
|---|---|---|---|
| Change Summary | Tables (Entities) | ✅ | Include added/modified/deleted table components |
| Change Summary | Attributes (Columns) | ✅ | Include attribute changes when detectable from Entity.xml and related metadata |
| Change Summary | App Modules / Model-driven apps | ✅ | Include app module changes |
| Change Summary | App Module Site Maps | ✅ | Include sitemap changes |
| Change Summary | Power Automate Flows / Processes (Workflows) | ✅ | Include flow/process changes when present in unpacked solution |
| Change Summary | Relationships | ✅ | Include relationship changes |
| Change Summary | Web Resources | ✅ | Include web resource changes |
| Change Summary | Other solution components | ✅ | Include with best-effort type classification |
| Naming Rules | Custom tables | ✅ | Must carry publisher prefix (for example `tmy_`) |
| Naming Rules | Custom attributes | ✅ | Must carry publisher prefix (for example `tmy_`) |
| Naming Rules | System tables | ❌ | Exempt from naming-rule checks |
| Naming Rules | System attributes | ❌ | Exempt from naming-rule checks |
---
## Required Review Procedure (Follow In Order)
Use this exact order for every review:
1. Read all provided evidence inputs (`changes.status`, `changes.diff`, unpacked XML/component files, and this rule file).
2. Build the changed-component list using path mapping rules in this document.
3. Classify each component action as `Added`, `Modified`, or `Deleted` from evidence.
4. Produce human-readable summary lines (Section 0), applying compact mode when thresholds are met.
5. Evaluate naming rules only for in-scope custom tables and custom attributes (Section 1 and Section 2).
7. If no in-scope items exist for a section, explicitly output the required empty-state sentence.
Do not skip steps. Do not reorder steps.
### Evidence Precedence
When evidence sources disagree, use this precedence:
1. `changes.status` for Added/Modified/Deleted file action detection.
2. `changes.diff` for change evidence details.
3. Unpacked XML/component files for display names, attribute details, flow trigger/actions, and descriptions.
### Hard Constraints (No Ambiguity)
- Never invent component names, physical names, flow names, or attributes.
- Never auto-correct or normalize physical names. Keep exact names from evidence.
- If evidence is insufficient, explicitly write `not available from current evidence`.
- Use only component names that appear in provided evidence inputs.
- Do not apply naming-rule checks outside custom tables/custom attributes.
---
## Workflow Prompt Directives
Apply these directives exactly when generating the review output:
- For change summary, include all component types defined in this rules document.
- Classify component type and action from changed file paths in `changes.status` first (per path mapping in this document); do not infer changed component types from name mentions in XML bodies.
- Only report relationship component changes when corresponding changed paths map to relationship files (`Other/Relationships*.xml` or `Other/Relationships/*.xml`, including solution-prefixed variants).
- If only table-related files changed under `Entities/<table>/...`, report those as table/table-metadata changes and do not emit relationship rows unless relationship-mapped files are changed.
- For naming-rule evaluation, only evaluate components this rules document marks as in scope.
- For naming rules output, print only WARNING/ERROR violations; suppress PASS component entries.
- If no components or rule findings are in scope, explicitly output the required empty-state sentence(s) for the affected section.
---
## Component Change Classification Rules
Use these rules to determine **component type** and **change action** in the human summary.
### Change action mapping
- `Added`: file path appears as untracked/added in change evidence.
- `Modified`: file path appears as modified in change evidence.
- `Deleted`: file path appears as deleted in change evidence.
### Component type mapping by unpacked path (best effort)
- `src/solutions/Entities/<name>/Entity.xml` or `src/solutions/<solution>/Entities/<name>/Entity.xml` -> Table
- `src/solutions/Entities/<name>/...` or `src/solutions/<solution>/Entities/<name>/...` -> Table-related metadata (forms/views/ribbon)
- `src/solutions/AppModules/<name>/AppModule.xml` or `src/solutions/<solution>/AppModules/<name>/AppModule.xml` -> App Module
- `src/solutions/AppModuleSiteMaps/<name>/AppModuleSiteMap.xml` or `src/solutions/<solution>/AppModuleSiteMaps/<name>/AppModuleSiteMap.xml` -> App Module Sitemap
- `src/solutions/Other/Relationships*.xml` and `src/solutions/Other/Relationships/*.xml` (or with `<solution>/Other/...`) -> Relationship
- `src/solutions/Workflows/*.xml` (or with `<solution>/Workflows/...`) -> Power Automate Flow / Process
- `src/solutions/WebResources/**` (or with `<solution>/WebResources/...`) -> Web Resource
- everything else -> Other Component
### Table and attribute extraction rules
- Table physical name: use folder name under `Entities/<table>`.
- Table display name: use DisplayName from `Entity.xml` when available, otherwise derive from physical name.
- Attribute rows: extract custom attributes from `Entity.xml` for the same publisher prefix as the table.
- Attribute data type: use attribute type metadata from XML; if unavailable, report `Unknown`.
---
## Naming Rules
---
### PhysicalName must be in lowercase
**Applies to:** Table physical names, attribute physical names
**Definition:**
The full physical name — including the publisher prefix and the entity/attribute portion — must contain **no uppercase letters**. Every character must be either a lowercase letter (`a–z`), a digit (`0–9`), or an underscore (`_`).
**Rationale:**
Dataverse stores physical names in lowercase. Inconsistent casing in schema names before saving causes confusion during solution comparisons, ALM pipelines, and code references.
**Examples:**
| PhysicalName | Status | Reason |
|--------------------|--------|-------------------------------------|
| `tmy_order` | ✅ PASS | All lowercase |
| `tmy_orderdetail` | ✅ PASS | All lowercase |
| `tmy_Order` | ❌ FAIL | Contains uppercase `O` |
| `tmy_OrderDetail` | ❌ FAIL | Contains uppercase `O` and `D` |
| `TMY_order` | ❌ FAIL | Prefix contains uppercase letters |
**LLM Check Instruction:**
Scan the physical name character by character. If any character falls outside `[a-z0-9_]`, flag a violation of **PhysicalName must be in lowercase**.
---
### Table physical names must use singular form
**Applies to:** Table physical names only (not attributes)
**Definition:**
The entity portion of a custom table's physical name must represent a **single record concept**, not a collection. Use the singular form of the noun.
**Rationale:**
Each table record represents one instance of the entity. Plural naming implies a collection and conflicts with standard Dataverse conventions (e.g., `account`, `contact`, `invoice`).
**Examples:**
| PhysicalName | Status | Reason |
|---------------------|--------|-------------------------------------------|
| `tmy_order` | ✅ PASS | Singular |
| `tmy_orderdetail` | ✅ PASS | Singular |
| `tmy_product` | ✅ PASS | Singular |
| `tmy_orders` | ❌ FAIL | Plural — should be `tmy_order` |
| `tmy_orderdetails` | ❌ FAIL | Plural — should be `tmy_orderdetail` |
| `tmy_deliveries` | ❌ FAIL | Plural — should be `tmy_delivery` |
**Common plural suffixes to flag:** `-s`, `-es`, `-ies` (converted from `-y`), `-ves`
**LLM Check Instruction:**
Extract the entity portion of the name (everything after the first `_`). Check whether it ends with a common plural suffix (`s`, `es`, `ies`, `ves`). If yes, flag as a probable violation of **Table physical names must use singular form** and suggest the singular form. Note: some words are legitimately non-plural despite ending in `s` (e.g., `status`, `address`, `process`) — use context and common English to distinguish.
**Known non-violations (words ending in `s` that are singular):**
- `status`, `address`, `process`, `progress`, `access`, `class`, `canvas`
---
### Lookup attribute physical names must end with the suffix `id`
**Applies to:** Custom lookup (Many-to-One relationship) attributes only
**Definition:**
Any attribute that stores a reference to another table (i.e., a lookup field) must have a physical name ending in `id`. The portion before `id` must meaningfully represent the target table or relationship purpose.
**Rationale:**
Dataverse appends `id` to lookup physical names automatically when the schema name follows conventions. Enforcing this rule ensures schema names are set correctly before deployment and that lookup fields are immediately distinguishable from other field types during review.
**Examples:**
| PhysicalName | Status | Reason |
|-----------------------|--------|----------------------------------------------------------|
| `tmy_orderid` | ✅ PASS | Lookup to `tmy_order`, ends with `id` |
| `tmy_contactid` | ✅ PASS | Lookup to `contact`, ends with `id` |
| `tmy_parentaccountid` | ✅ PASS | Lookup to `account` (parent), ends with `id` |
| `tmy_order` | ❌ FAIL | Lookup field missing `id` suffix |
| `tmy_contact_lookup` | ❌ FAIL | Lookup field not ending with `id` |
| `tmy_ref_contact` | ❌ FAIL | Lookup field not ending with `id` |
**LLM Check Instruction:**
When reviewing an attribute that is of type **Lookup**, check that its physical name ends in `id`. If it does not, flag a violation of **Lookup attribute physical names must end with the suffix `id`**. This rule applies **only to lookup-type attributes** — do not apply to text, number, date, or other attribute types.
---
## Violation Severity Levels
| Severity | Description |
|----------|-----------------------------------------------------------------------------|
| ERROR | Must be fixed before deployment. Applies to all enforced naming rules in this document. |
| WARNING | Should be reviewed. Used for ambiguous plural detection edge cases. |
---
## LLM Review Output Format
Section title format is strict:
- Use markdown headings for section titles (for example, `## RULE EVALUATION MATRIX`, `## FINDINGS (NAMING RULES)`).
- Do not render section titles as numbered list items (for example, `1. RULE EVALUATION MATRIX`, `2. FINDINGS (NAMING RULES)`).
- Do not prefix mandatory section titles with bullets, numbering, or other list markers.
Start Section 0 with a compact summary table (no sentence-style intro lines).
Use this exact header order:
```
| Action | Display Name | PhysicalName |
|---|---|---|
| Added | Order Detail | tmy_oderdetail |
| Added | Order | tmy_order |
| Added | Blog App | tmy_blogapp |
```
Rules for this table:
- Prioritize display name first, then physical name.
- Use `Added`, `Modified`, or `Deleted` in `Action`.
- Include all in-scope changed components (tables, apps, flows/processes, relationships, web resources, others) as separate rows.
- If display name is unavailable, derive a readable display name from physical name/path.
- If physical name is unavailable, use best-effort path-derived identifier.
- For relationship components, format `Display Name` as `Relationship: <logical name>`.
- If there are no component changes, output one row:
- `| None | No component changes found | N/A |`
### Markdown Table Formatting Requirements
Use strict markdown table formatting for all tables in the output:
- Use this exact header in Section 0:
| Action | Display Name | PhysicalName |
|---|---|---|
| <Action> | <Display Name> | <PhysicalName> |
- Use `Added`, `Modified`, or `Deleted` in `Action`.
- Do not pad cells with alignment spaces for visual width.
- Do not emit tabs in table rows.
- Trim leading/trailing spaces inside each cell value.
- For relationship rows, do not use file names such as `Relationships.xml` as `Display Name` when a logical name is available from evidence.
- Ensure markdown tables are rendered as tables by layout:
- Add one blank line before every table header row.
- Add one blank line after every table block before prose text.
- Do not place table headers directly under list items.
- Do not prefix lines immediately before table headers with list markers (`-`, `*`, `1.`).
### Large Change Set Summary Mode
When the number of changed components is large, prefer compact summary output.
Use compact mode when either of these is true:
- 10 or more changed components overall, or
- 5 or more changed tables.
In compact mode:
- Summarize at table level (physical names) for added/updated/deleted tables.
- Do not expand to attribute-level details unless a specific naming-rule finding requires it.
- If available from XML, include table display name in short form: `<physical name> (<display name>)`.
- Use short grouped lines such as:
- `Added tables: tmy_order (Order), tmy_oderdetail (Order Detail), ...`
- `Updated tables: ...`
- `Deleted tables: ...`
- `Added flows/processes: Flow A, Flow B, ...`
- `Updated flows/processes: ...`
- `Deleted flows/processes: ...`
In compact mode, attribute-level rows are optional unless needed to explain a naming-rule finding.
For flows/processes, include best-effort high-level step result summaries when available from workflow metadata.
Use concise lines like:
- `Flow <name>: trigger <trigger>; then <action 1>; then <action 2>; result <outcome summary>.`
Do not invent step names. If step details are not available in evidence, write:
- `Flow <name>: step-level details not available from current unpacked evidence.`
After the compact summary table, continue with concise component-level lines in this style:
```
- Added table <table physical name> - <table display name>
| Attribute | Display Name | Data Type |
|---|---|---|
| <attribute physical name> | <attribute display name> | <attribute data type> |
- Added app module <component physical name>
- Modified flow/process <component physical name>
- Deleted relationship <component physical name>
```
Use `Added`, `Updated`, or `Deleted` based on diff evidence.
If a changed table has no in-scope attribute changes, include the table line and write: `No in-scope attribute changes`.
If no component changes are found, write: `No component changes found.`
### Mandatory Naming Section: RULE EVALUATION (NAMING RULES)
Use a single merged naming section only.
Do not output separate sections named `RULE EVALUATION MATRIX` and `FINDINGS (NAMING RULES)`.
Include only components with WARNING/ERROR violations. Do not print PASS-only entries.
If no naming-rule violations exist, output only:
```
## RULE EVALUATION (NAMING RULES)
No naming-rule violations found.
```
When violations exist, output each finding in this structure:
```
## RULE EVALUATION (NAMING RULES)
COMPONENT: <physical name>
TYPE: <Table | Attribute — Lookup | Attribute — Other>
RULE VIOLATED: <PhysicalName must be in lowercase | Table physical names must use singular form | Lookup attribute physical names must end with the suffix `id`>
SEVERITY: <ERROR | WARNING>
REASON: <one-line explanation>
SUGGESTED FIX: <corrected logical name, if applicable>
```
Use `N/A` only when explicitly needed inside the reason text.
Do not apply naming-rule checks to non-table/non-attribute components (apps, flows, relationships, web resources, and other components).
**Example output:**
```
COMPONENT: tmy_Orders
TYPE: Table
RULE VIOLATED: PhysicalName must be in lowercase; Table physical names must use singular form
SEVERITY: ERROR
REASON: Contains uppercase letter 'O'; entity name is plural.
SUGGESTED FIX: tmy_order
COMPONENT: tmy_contactid
TYPE: Attribute — Lookup
RULE VIOLATED: NONE
SEVERITY: PASS
REASON: Lowercase, lookup field correctly ends with 'id'.
COMPONENT: tmy_contact_ref
TYPE: Attribute — Lookup
RULE VIOLATED: Lookup attribute physical names must end with the suffix `id`
SEVERITY: ERROR
REASON: Lookup attribute does not end with 'id'.
SUGGESTED FIX: tmy_contactid
```
---
## Out of Scope (Future Rules)
The following are **not yet enforced** but are candidates for future rules:
- Publisher prefix validation (ensuring all custom components use the correct approved prefix)
- Choice (option set) naming conventions
- Relationship schema name conventions
- Attribute naming conventions by data type (e.g., boolean fields prefixed with `is` or `has`)
- Maximum logical name length
---
*Last updated: 2026-05-24 | Change summary scope: all component types | Naming-rule scope: custom tables and custom attributes only*
GitHub Environment
Here are the Environment secrets and variables that I already set up:
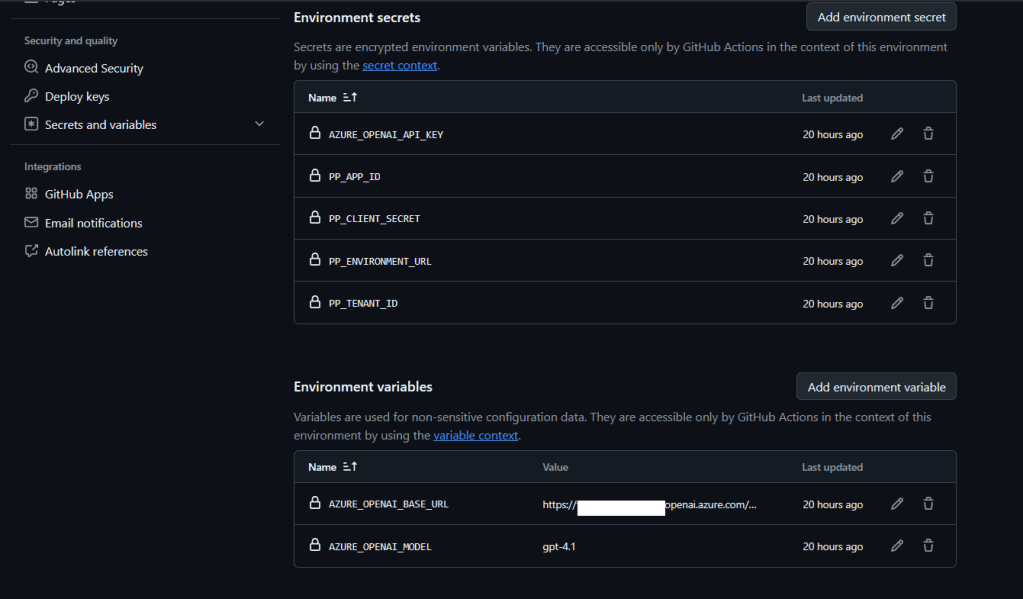
GitHub Environment secrets and variables
Demo
To trigger the Export Power Platform Solution, we just need to go to Actions > Export Power Platform Solutions > select the Branch that we want > input the solution name > hit the Run workflow button:
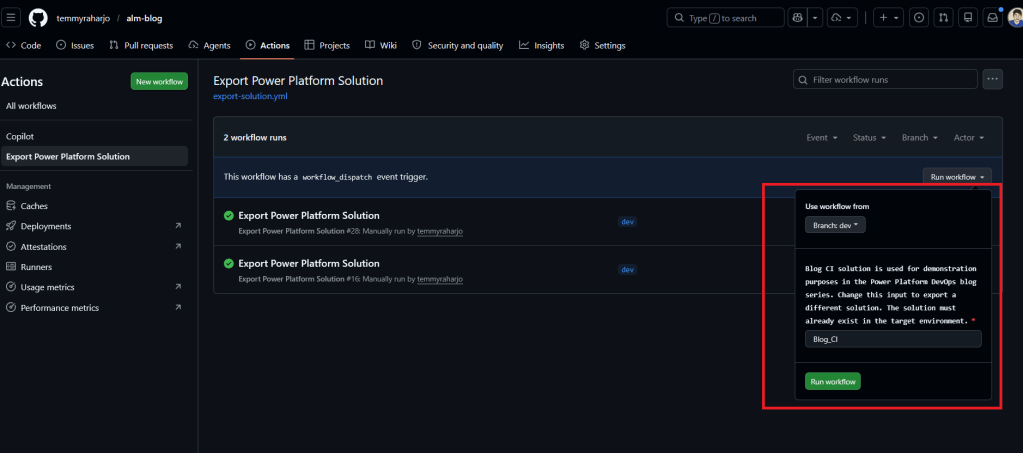
Run the workflow
Here are the sample of the result:
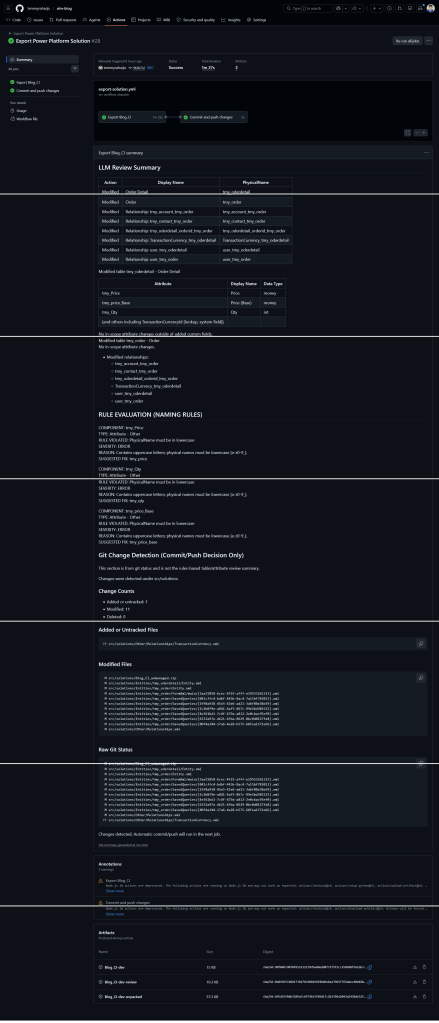
Sample summarization
Summary
Tracking changes across Power Platform components used to mean staring at raw XML diffs and hoping you caught something important. By wiring GitHub Actions to an LLM, that review becomes automatic; every export produces a plain-English summary of what changed, what looks risky, and what's worth a closer look before promoting to a higher environment. The setup is lightweight, fits into an existing CI pipeline, and scales with your team's output. From here, you could extend it to flag breaking changes against a known schema, route summaries to a Teams channel, or gate deployments on review approval. The noise doesn't have to be your problem anymore.
Happy CRM-ing! 🚀
Leave a comment
Your comment is sent privately to the author and isn't published on the site.